CPU affinity#
Before you start#
CPU affinity is the name for the mechanism by which a process is bound to a specific CPU core or a set of cores.
For some background here's an article from 2003 when this capability was introduced to Linux for the first time.
Another good overview is provided by Glenn Lockwood of the San Diego Supercomputer Center.
NUMA#
Or as it should be, ccNUMA, cache coherent non uniform memory access. All modern multi socket computers look something like the diagram below with multiple levels of memory and some of this being distributed across the system.
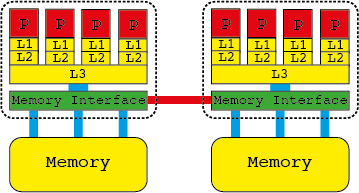
Memory is allocated by the operating system when asked to do so by your code, but the physical location is not defined until the moment at which the memory page is accessed. The default is to place the page on the closest physical memory, i.e. the memory directly attached to the socket, as this provides the highest performance. If the thread accessing the memory moves to the other socket the memory will not follow!
Cache coherence is the name of the process that ensures that if one core updates information that is also in the cache of another core, the change is propagated.
Exposing the problem#
Apart from the memory access already discussed, if we have exclusive nodes with only one MPI task per node, then there isn't a problem as everything will work "as designed". The problems begin when we have shared nodes, that is to say nodes with more than one MPI task per system image. These tasks may all belong to the same user. In this case the default settings can result in some very strange and unwanted behavior.
If we start mixing flavors of MPI on nodes then things can get really fun...
Hybrid codes, that is to say mixing MPI with threads, e.g. using OpenMP, also present a challenge. By default, Linux threads inherit the mask of the spawning process so if you want your threads to have free use of all the available cores please take care!
How do I use CPU affinity?#
The truthful and unhelpful answer is:
#define _GNU_SOURCE /* See feature_test_macros(7) */
#include <sched.h>
int sched_setaffinity(pid_t pid, size_t cpusetsize, cpu_set_t *mask);
int sched_getaffinity(pid_t pid, size_t cpusetsize, cpu_set_t *mask);
Note on Masks#
When talking about affinity we use the term "mask" or "bit mask", which is a convenient way of representing which cores are part of a CPU set. If we have an 8-core system, then the following mask means that the process is bound to CPUs 7 and 8.
This number can be conveniently written in hexadecimal as c0 (192 in decimal)
and so if we query the system regarding CPU masks we will see something like:
pid 8092's current affinity mask: 000111000000
pid 8097's current affinity mask: 000111000000000000000000
Slurm and srun#
As well as the traditional MPI process launchers (mpirun) there is also srun
, which is Slurm's native job starter. Its main advantages are its tight
integration with the batch system and speed at starting large jobs.
In order to set and view CPU affinity with srun one needs to pass the
--cpu_bind flag with some options. We strongly suggest that you always ask for
--verbose, which will print out the affinity mask.
To bind by rank:
:~> srun -N 1 -n 4 -c 1 --cpu_bind=verbose,rank ./hi 1
cpu_bind=RANK - b370, task 0 0 [5326]: mask 0x1 set
cpu_bind=RANK - b370, task 1 1 [5327]: mask 0x2 set
cpu_bind=RANK - b370, task 3 3 [5329]: mask 0x8 set
cpu_bind=RANK - b370, task 2 2 [5328]: mask 0x4 set
Hello world, b370
0: sleep(1)
0: bye-bye
Hello world, b370
2: sleep(1)
2: bye-bye
Hello world, b370
1: sleep(1)
1: bye-bye
Hello world, b370
3: sleep(1)
3: bye-bye
Binding by rank
Please be aware that binding by rank is only recommended for pure MPI codes as any OpenMP or threaded part will also be confined to one CPU!
To bind to sockets:
:~> srun -N 1 -n 4 -c 4 --cpu_bind=verbose,sockets ./hi 1
cpu_bind=MASK - b370, task 1 1 [5376]: mask 0xff00 set
cpu_bind=MASK - b370, task 2 2 [5377]: mask 0xff set
cpu_bind=MASK - b370, task 0 0 [5375]: mask 0xff set
cpu_bind=MASK - b370, task 3 3 [5378]: mask 0xff00 set
Hello world, b370
0: sleep(1)
0: bye-bye
Hello world, b370
2: sleep(1)
2: bye-bye
Hello world, b370
1: sleep(1)
1: bye-bye
Hello world, b370
3: sleep(1)
3: bye-bye
To bind with whatever mask you feel like:
:~> srun -N 1 -n 4 -c 4 --cpu_bind=verbose,mask_cpu:f,f0,f00,f000 ./hi 1
cpu_bind=MASK - b370, task 0 0 [5408]: mask 0xf set
cpu_bind=MASK - b370, task 1 1 [5409]: mask 0xf0 set
cpu_bind=MASK - b370, task 2 2 [5410]: mask 0xf00 set
cpu_bind=MASK - b370, task 3 3 [5411]: mask 0xf000 set
Hello world, b370
0: sleep(1)
0: bye-bye
Hello world, b370
1: sleep(1)
1: bye-bye
Hello world, b370
3: sleep(1)
3: bye-bye
Hello world, b370
2: sleep(1)
2: bye-bye
In the case of there being an exact match between the number of tasks and the number of cores srun will bind by rank but by default there is no CPU binding
:~> srun -N 1 -n 8 -c 1 --cpu_bind=verbose ./hi 1
cpu_bind=MASK - b370, task 0 0 [5467]: mask 0xffff set
cpu_bind=MASK - b370, task 7 7 [5474]: mask 0xffff set
cpu_bind=MASK - b370, task 6 6 [5473]: mask 0xffff set
cpu_bind=MASK - b370, task 5 5 [5472]: mask 0xffff set
cpu_bind=MASK - b370, task 1 1 [5468]: mask 0xffff set
cpu_bind=MASK - b370, task 4 4 [5471]: mask 0xffff set
cpu_bind=MASK - b370, task 2 2 [5469]: mask 0xffff set
cpu_bind=MASK - b370, task 3 3 [5470]: mask 0xffff set
This may well result in sub optimal performance as one has to rely on the OS scheduler to (not) move things around.
See the --cpu_bind section of the srun man
page for all the details.
OpenMP CPU affinity#
There are two main ways that OpenMP is used on the clusters.
- A single node OpenMP code
- A hybrid code with one OpenMP domain per rank
For both Intel and GNU OpenMP there are environmental variables which control how OpenMP threads are bound to cores.
The first step for both is to set the number of OpenMP threads per job (case 1) or MPI rank (case 2). Here we set it to 8
Intel#
The variable here is KMP_AFFINITY
export KMP_AFFINITY=verbose,scatter # place the threads as far apart as possible
export KMP_AFFINITY=verbose,compact # pack the treads as close as possible to each other
The official documentation can be found here
GNU#
With gcc one needs to set either OMP_PROC_BIND
export OMP_PROC_BIND=SPREAD # place the threads as far apart as possible
export OMP_PROC_BIND=CLOSE # pack the treads as close as possible to each other
or GOMP_CPU_AFFINITY, which takes a list of CPUs
GOMP_CPU_AFFINITY="0 2 4 6 8 10 12 14" # place the threads on CPUs 0,2,4,6,8,10,12,14 in this order.
GOMP_CPU_AFFINITY="0 8 2 10 4 12 6 14" # place the threads on CPUs 0,8,2,10,4,12,6,14 in this order.
The official documentation can be found here
CGroups#
As CGroups and tasksets both do more or less the same thing it's hardly surprising that they aren't very complementary.
The basic outcome is that if the restrictions imposed aren't compatible then there's an error and the executable isn't run. Even if the restrictions imposed are compatible they may still give unexpected results.
One can even have unexpected behaviour with just CGroups! A nice example of this
is creating an 8 core CGroup and then using IntelMPI with pinning activated to
run srun -n 12 ./mycode. The first eight processes have the following
masks